- Normalization in DBMS
- 2. Need of Normalization in DBMS
- [[#2. Need of Normalization in DBMS#1. Insertion Anomaly in DBMS|1. Insertion Anomaly in DBMS]]
- [[#2. Need of Normalization in DBMS#2. Updation Anomaly in DBMS|2. Updation Anomaly in DBMS]]
- [[#2. Need of Normalization in DBMS#3. Deletion Anomaly in DBMS|3. Deletion Anomaly in DBMS]]
- Primary Key and Non-key attributes
- NEXT: Types of Normal Forms in DBMS
Normalization in DBMS
-
Normalization in DBMS is a technique using which you can organize the data in the database tables so that:
- There is less repetition of data,
- A large set of data is structured into a bunch of smaller tables,
- and the tables have a proper relationship between them.
-
DBMS Normalization is a systematic approach to decompose (break down) tables to eliminate
- data redundancy(repetition)
- undesirable characteristics like
- Insertion anomaly
- Update anomaly
- Delete anomaly
-
It is a multi-step process that puts data into tabular form, removes duplicate data, and set up the relationship between tables.
2. Need of Normalization in DBMS
Normalization is required for,
- Eliminating redundant(useless) data, therefore handling data integrity,
- Repetition of data increases the chances of inconsistent data.
- Normalization helps in keeping data consistent by storing the data in one table and referencing it everywhere else.
- Storage optimization although that is not an issue these days because Database storage is cheap.
-
Breaking down large tables into smaller tables with relationships, so it makes the database structure more scalable and adaptable.
-
Ensuring data dependencies make sense i.e. data is logically stored.
- If a table is not properly normalized and has data redundancy(repetition) then it will not only eat up extra memory spacebut will also make it difficult for you to handle and update the data in the database, without losing data.
Insertion, Updation, and Deletion Anomalies are very frequent if the database is not normalized.
To understand these anomalies let us take an example of a Student table.
| rollno | name | branch | hod | office_tel |
|---|---|---|---|---|
| 401 | Akon | CSE | Mr. X | 53337 |
| 402 | Bkon | CSE | Mr. X | 53337 |
| 403 | Ckon | CSE | Mr. X | 53337 |
| 404 | Dkon | CSE | Mr. X | 53337 |
In the table above, we have data for four Computer Sci. students.
As we can see, data for the fields branch, hod(Head of Department), and office_tel are repeated for the students who are in the same branch in the college, this is Data Redundancy.
1. Insertion Anomaly in DBMS
- Suppose for a new admission, until and unless a student opts for a branch, data of the student cannot be inserted, or else we will have to set the branch information as NULL.
- Also, if we have to insert data for 100 students of the same branch, then the branch information will be repeated for all those 100 students.
- These scenarios are nothing but Insertion anomalies.
- If you have to repeat the same data in every row of data, it’s better to keep the data separately and reference that data in each row.
- So in the above table, we can keep the branch information separately, and just use the branch_id in the student table, where branch_id can be used to get the branch information.
2. Updation Anomaly in DBMS
-
What if Mr. X leaves the college? or Mr. X is no longer the HOD of the computer science department? In that case, all the student records will have to be updated, and if by mistake we miss any record, it will lead to data inconsistency.
-
This is an Updation anomaly because you need to update all the records in your table just because one piece of information got changed.
3. Deletion Anomaly in DBMS
-
In our Student table, two different pieces of information are kept together, the Student information and the Branch information.
-
So if only a single student is enrolled in a branch, and that student leaves the college, or for some reason, the entry for the student is deleted, we will lose the branch information too.
-
So never in DBMS, we should keep two different entities together, which in the above example is Student and branch,
The solution for all the three anomalies described above is to keep the student information and the branch information in two different tables. And use the branch_id in the student table to reference the branch.
Primary Key and Non-key attributes
Before we move on to learn different Normal Forms in DBMS, let’s first understand what is a primary key and what are non-key attributes.
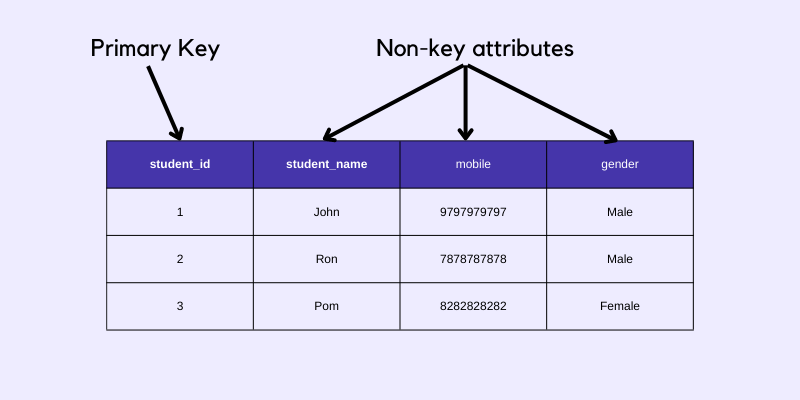
As you can see in the table above, the student_id column is a primary key because using the student_id value we can uniquely identify each row of data, hence the remaining columns then become the non-key attributes.