INDEX
- QUE 2)Describe the three level schema architecture. Why do we need mappings between schema levels? How do different sehema definition languages support this architecture?
- [[#QUE 2)Describe the three level schema architecture. Why do we need mappings between schema levels? How do different sehema definition languages support this architecture?#Three-Level Schema Architecture:|Three-Level Schema Architecture:]]
- [[#QUE 2)Describe the three level schema architecture. Why do we need mappings between schema levels? How do different sehema definition languages support this architecture?#Need for Mappings Between Schema Levels:|Need for Mappings Between Schema Levels:]]
- [[#QUE 2)Describe the three level schema architecture. Why do we need mappings between schema levels? How do different sehema definition languages support this architecture?#Schema Definition Languages and Support:|Schema Definition Languages and Support:]]
- QUE 3)Explain the concept of log in database recovery. Distinguish between deferred update and immediate update log based recovery techniques?
- [[#QUE 3)Explain the concept of log in database recovery. Distinguish between deferred update and immediate update log based recovery techniques?#Log-Based Recovery in DBMS:|Log-Based Recovery in DBMS:]]
- [[#QUE 3)Explain the concept of log in database recovery. Distinguish between deferred update and immediate update log based recovery techniques?#Key Differences Between Deferred Update and Immediate Update:|Key Differences Between Deferred Update and Immediate Update:]]
- QUE 4) Write short note on ANY THREE of the following:
- QUE 5)Construct an E-R. Diagram for a car insurance company that has a set of customers, each of whom owns one/more cars. Each car has associated with it zero to any number of recorded accidents. Make necessary assumptions wherever required.
- QUE 6)Explain what is meant by redundant information and loss of information. Explain why each of these properties may indicate a bad relational database design?
- QUE 7)
QUE 1) Describe the three level schema architecture. Why do we need mappings between schema levels? How do different sehema definition languages support this architecture?
ANS:
Certainly! Let’s explore the three-level schema architecture, the need for mappings between schema levels, and how different schema definition languages support this architecture.
Three-Level Schema Architecture:
The three-level schema architecture, also known as the ANSI/SPARC architecture, separates a database system into three distinct levels:
-
External Level (View Level):
- The external level represents the user’s view of the database.
- It defines various user views or external schemas.
- Each user or application interacts with the database through their personalized view.
- The external schema describes what data the user can access and how they can access it.
- Example: Different departments within an organization may have different views of employee data (e.g., HR views, finance views).
-
Conceptual Level (Logical Level):
- The conceptual level describes the overall logical structure of the entire database.
- It provides a global view of the data.
- The conceptual schema defines the entities, their attributes, and the relationships among them.
- It is independent of any specific DBMS implementation.
- Example: The conceptual schema defines the relationships between employees, departments, and projects.
-
Internal Level (Physical Level):
- The internal level describes the physical storage structure of the database.
- It deals with low-level data structures and storage details.
- The internal schema specifies how data is stored in blocks, access paths (e.g., indexes), data compression, encryption techniques, and optimization strategies.
- Example: The internal schema defines the B-tree index structure for efficient data retrieval.
Need for Mappings Between Schema Levels:
-
Data Independence:
- Mappings allow us to achieve data independence by separating the user’s view from the physical storage details.
- Changes at one level should not affect other levels.
- Users can work with their personalized views without worrying about underlying changes.
-
Schema Evolution:
- As requirements change, the conceptual schema may evolve.
- Mappings ensure that changes to the conceptual schema do not impact external views or internal storage.
-
Security and Privacy:
- Mappings allow controlled access to data.
- External views can be customized to show only relevant information.
Schema Definition Languages and Support:
Different schema definition languages facilitate the three-level architecture:
-
Entity Relationship Diagram (ERD):
- ERD is a graphical representation of the conceptual schema.
- It shows entities, attributes, and relationships.
- ERD tools help design and visualize the database structure.
-
Unified Modeling Language (UML):
- UML includes class diagrams that can represent the conceptual schema.
- It extends beyond databases to cover software modeling.
-
Object Role Modeling (ORM):
- ORM focuses on conceptual modeling.
- It uses natural language constructs to define entities, roles, and relationships.
-
SQL Data Definition Language (DDL):
- SQL DDL statements (e.g.,
CREATE TABLE,ALTER TABLE) define the internal schema. - They specify the physical storage details.
- SQL DDL statements (e.g.,
In summary, the three-level schema architecture ensures data independence, security, and efficient management of database systems. Mappings between schema levels allow seamless communication between users and the underlying data123. 🌐🔍📊
QUE 2)Describe the three level schema architecture. Why do we need mappings between schema levels? How do different sehema definition languages support this architecture?
ANS:
Certainly! Let’s delve into the three-level schema architecture, the importance of mappings between schema levels, and how various schema definition languages support this architecture.
Three-Level Schema Architecture:
The three-level schema architecture, also known as the ANSI/SPARC architecture, is a framework used to describe the structure of a specific database system. It separates the database into three distinct levels:
-
External Level (View Level):
- The external level represents the user’s view of the database.
- It defines various user views or external schemas.
- Each user or application interacts with the database through their personalized view.
- The external schema describes what data the user can access and how they can access it.
- Example: Different departments within an organization may have different views of employee data (e.g., HR views, finance views).
-
Conceptual Level (Logical Level):
- The conceptual level describes the overall logical structure of the entire database.
- It provides a global view of the data.
- The conceptual schema defines the entities, their attributes, and the relationships among them.
- It is independent of any specific DBMS implementation.
- Example: The conceptual schema defines the relationships between employees, departments, and projects.
-
Internal Level (Physical Level):
- The internal level describes the physical storage structure of the database.
- It deals with low-level data structures and storage details.
- The internal schema specifies how data is stored in blocks, access paths (e.g., indexes), data compression, encryption techniques, and optimization strategies.
- Example: The internal schema defines the B-tree index structure for efficient data retrieval.
Need for Mappings Between Schema Levels:
-
Data Independence:
- Mappings allow us to achieve data independence by separating the user’s view from the physical storage details.
- Changes at one level should not affect other levels.
- Users can work with their personalized views without worrying about underlying changes.
-
Schema Evolution:
- As requirements change, the conceptual schema may evolve.
- Mappings ensure that changes to the conceptual schema do not impact external views or internal storage.
-
Security and Privacy:
- Mappings allow controlled access to data.
- External views can be customized to show only relevant information.
Schema Definition Languages and Support:
Different schema definition languages facilitate the three-level architecture:
-
Entity Relationship Diagram (ERD):
- ERD is a graphical representation of the conceptual schema.
- It shows entities, attributes, and relationships.
- ERD tools help design and visualize the database structure.
-
Unified Modeling Language (UML):
- UML includes class diagrams that can represent the conceptual schema.
- It extends beyond databases to cover software modeling.
-
Object Role Modeling (ORM):
- ORM focuses on conceptual modeling.
- It uses natural language constructs to define entities, roles, and relationships.
In summary, the three-level schema architecture ensures data independence, security, and efficient management of database systems. Mappings between schema levels allow seamless communication between users and the underlying data12. 🌐🔍📊
QUE 3)Explain the concept of log in database recovery. Distinguish between deferred update and immediate update log based recovery techniques?
ANS:
Certainly! Let’s dive into the concept of log-based recovery in databases and explore the differences between deferred update and immediate update log-based recovery techniques.
Log-Based Recovery in DBMS:
Log-based recovery is a technique used in database management systems (DBMS) to recover a database to a consistent state in the event of a failure or crash. It relies on maintaining a transaction log, which is a record of all the transactions performed on the database. Here are the key components:
-
Log and Log Records:
- The log is a sequence of log records, recording all the updated activities in the database.
- In stable storage, logs for each transaction are maintained.
- Any operation performed on the database is recorded in the log.
- Prior to performing any modification to the database, an updated log record is created to reflect that modification.
- An update log record is represented as:
<Ti, Xj, V1, V2>with the following fields:- Transaction identifier: A unique identifier of the transaction that performed the write operation.
- Data item: A unique identifier of the data item written.
- Old value: Value of the data item prior to the write.
- New value: Value of the data item after the write operation.
- Other types of log records include:
<Ti start>: Contains information about when a transaction Ti starts.<Ti commit>: Contains information about when a transaction Ti commits.<Ti abort>: Contains information about when a transaction Ti aborts.
-
Undo and Redo Operations:
- Because all database modifications must be preceded by the creation of a log record, the system has available both the old value prior to the modification of the data item and the new value that is to be written for the data item.
- This allows the system to perform the following operations as appropriate:
- Undo: Using a log record sets the data item specified in the log record to the old value.
- Redo: Using a log record sets the data item specified in the log record to the new value.
-
Deferred Modification Technique:
- If the transaction does not modify the database until it has partially committed, it is said to use deferred modification technique.
- In this approach, the database modification is deferred or delayed until the last operation of the transaction is executed.
- Updates are recorded in the log before they are applied to the database, making recovery still possible.
-
Immediate Modification Technique:
- If database modifications occur while the transaction is still active, it is said to use immediate modification technique.
- In this approach, the database may be updated by some operations of a transaction before the transaction reaches its commit point.
- However, these operations are recorded in a log on disk before they are applied to the database, making recovery still possible.
Key Differences Between Deferred Update and Immediate Update:
-
Deferred Update:
- The database modification occurs only after the transaction has partially committed.
- Updates are recorded in the log but not immediately applied to the database.
- Recovery is possible because the database remains unchanged until the transaction fully commits.
-
Immediate Update:
- The database may be updated by some operations of a transaction while the transaction is still active.
- These operations are recorded in the log before they are applied to the database.
- Recovery is still possible because the log maintains a record of the updates.
In summary, log-based recovery ensures that transactions are either fully committed or fully aborted, and it allows the system to recover from failures by consulting the transaction log1. 🌐🔍📊
QUE 4) Write short note on ANY THREE of the following:
a) ACID properties of transaction
b) Database security
c) Types of database failures
d) Check points in a transaction**
ANS:
Certainly! Let’s delve into each of these topics:
-
ACID Properties of Transactions:
- ACID stands for Atomicity, Consistency, Isolation, and Durability. These properties ensure the reliability and integrity of database transactions.
- Atomicity: A transaction is either fully executed or not executed at all. No partial changes occur.
- Consistency: The database remains in a valid state before and after a transaction. Integrity constraints are maintained.
- Isolation: Multiple transactions can run concurrently without interfering with each other. Changes made by one transaction are not visible to others until committed.
- Durability: Once a transaction is committed, its changes are permanent even in the face of system failures.
- ACID properties guarantee data validity despite errors, power failures, or other mishaps 12.
-
Database Security:
- Database security ensures confidentiality, integrity, and accessibility of data.
- Aspects covered include:
- Securing the database itself.
- Protecting the database management system (DBMS).
- Safeguarding associated applications.
- Ensuring physical security of servers and network infrastructure.
- Threats include insider dangers, software vulnerabilities, SQL/NoSQL injection, malware, etc. Best practices involve access controls, encryption, and regular audits 34.
-
Types of Database Failures:
- Transaction Failure:
- Occurs when a transaction cannot execute or reaches an unrecoverable state.
- Reasons: logical errors, system errors, or system crash.
- Data-Transfer Failure:
- Disk failure during data transfer, leading to data loss.
- Causes: disk head crash, bad sectors, read-write errors.
- System Crash:
- Hardware or software breakdown causing abrupt system stop.
- Fail-stop assumption: non-volatile storage remains unaffected.
- Proper recovery techniques (e.g., checkpoints) mitigate these failures 5.
- Transaction Failure:
-
Checkpoints in a Transaction:
- Checkpoints declare a consistent state before which all transactions were committed.
- Purpose:
- Reduce storage space used by transaction logs.
- Address system crash scenarios.
- Types:
- Automatic Checkpoint: Set at regular intervals (e.g., hourly or daily).
- Manual Checkpoint: Manually set by administrators for smaller databases.
- Recovery system reads logs backward from the end to the last checkpoint, ensuring data integrity 6.
Remember, these concepts play crucial roles in maintaining robust and secure database systems! 🛡️🔐
QUE 5)Construct an E-R. Diagram for a car insurance company that has a set of customers, each of whom owns one/more cars. Each car has associated with it zero to any number of recorded accidents. Make necessary assumptions wherever required.
ANS:
Certainly! Let’s create an Entity-Relationship (E-R) diagram for the car insurance company based on the given requirements:
-
Entities:
- Customer: Represents the customers of the car insurance company.
- Car: Represents the cars owned by customers.
- Accident: Represents recorded accidents associated with each car.
-
Attributes:
- Customer:
- CustomerID (Primary Key)
- Name
- Address
- Contact Number
- Car:
- CarID (Primary Key)
- Make
- Model
- Year
- Registration Number
- Accident:
- AccidentID (Primary Key)
- Date
- Description
- Damage Details
- Customer:
-
Relationships:
- Owns: A customer can own one or more cars.
- Has: Each car can have zero to any number of recorded accidents.
-
Assumptions:
- A customer can own multiple cars, and each car belongs to only one customer.
- An accident is associated with a specific car.
Here’s the simplified E-R diagram:
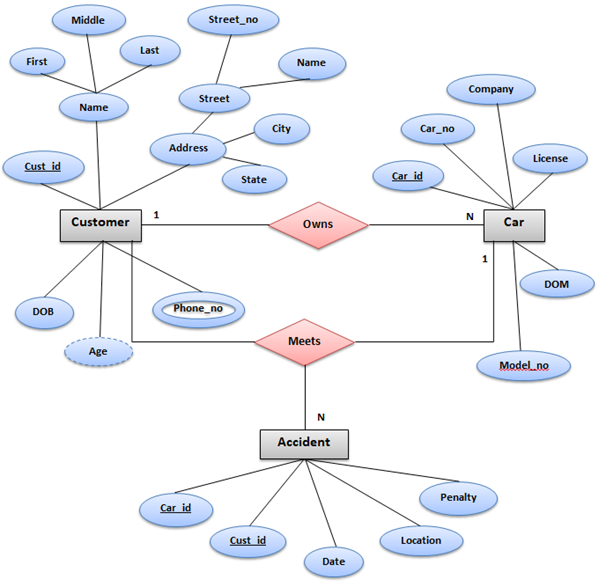
!Car Insurance E-R Diagram
Feel free to expand or modify this diagram based on additional requirements or business rules specific to the car insurance company! 🚗🔍
QUE 6)Explain what is meant by redundant information and loss of information. Explain why each of these properties may indicate a bad relational database design?
ANS:
Certainly! Let’s delve into the concepts of redundant information and loss of information in the context of relational databases:
-
Redundant Information:
- Definition: Redundancy refers to having multiple copies of the same data stored unnecessarily within a database.
- Causes of Redundancy:
- Lack of Normalization: When a database is not properly normalized (organized into tables), redundancy can occur.
- Incomplete Updates: Inconsistent updates across duplicated data instances lead to redundancy.
- Poor Database Design: Unnecessary duplicate columns or tables contribute to redundancy.
- Denormalization: Intentional duplication for query performance can introduce redundancy.
- Effects of Redundancy:
- Data Inconsistency: Updates not uniformly applied lead to inconsistent data.
- Increased Storage Requirements: Redundant data consumes extra storage space.
- Complexity in Maintenance: Managing redundant data becomes challenging.
- Data Integrity Issues: Accuracy and reliability of data are compromised 1.
-
Loss of Information:
- Definition: Loss of information occurs when relevant data is missing or unintentionally removed from the database.
- Causes of Loss of Information:
- Deletion Anomalies: Deleting a record may unintentionally remove related data.
- Update Anomalies: Updating one copy of data without updating others leads to loss.
- Insertion Anomalies: Inability to insert data due to missing related information.
- Impact of Loss of Information:
- Data Inconsistency: Incomplete or missing data affects decision-making.
- Storage Efficiency: Loss of information may reduce storage requirements.
- Maintenance Challenges: Managing incomplete data becomes complex.
- Data Integrity: Incomplete data compromises accuracy and reliability 2.
-
Why These Properties Indicate Bad Relational Database Design:
- Redundancy:
- Negative Impact: Excessive redundancy leads to inefficiency, inconsistency, and complexity.
- Violation of Normalization Principles: Redundancy violates normalization rules, which aim to minimize redundancy.
- Difficulty in Maintenance: Managing redundant data complicates maintenance.
- Loss of Information:
- Data Integrity Risk: Incomplete or lost data undermines data integrity.
- Inefficient Operations: Missing information hampers efficient querying and reporting.
- Maintenance Challenges: Handling incomplete data requires extra effort.
- Poor Design Practice: Loss of information indicates suboptimal schema design 13.
- Redundancy:
In summary, a well-designed relational database should minimize redundancy and avoid loss of information to ensure data accuracy, efficiency, and ease of maintenance. 🛢️🔍
QUE 7)
What is indexing? Explain the different types of indexes with an example of each. ANS: Indexing in databases is a technique used to improve data retrieval performance by minimizing the number of disk accesses required to fulfill queries. It involves creating data structures that allow for quick access to specific data within a database. Let’s explore the different types of indexes along with examples:
-
Primary Index:
- An ordered file with fixed-length records.
- Contains two fields: the primary key and a pointer to the corresponding data block.
- Ensures a one-to-one relationship between index entries and data records.
- Example: Imagine a student database where the primary index is based on student roll numbers.
-
Dense Index:
- A record is created for every search key value in the database.
- Each index record contains the search key and points to the actual data record on disk.
- Faster search but requires more space for index records.
- Example: An employee database with dense indexing based on employee IDs.
-
Sparse Index:
- Index records appear only for some search-key values.
- Each item points to a block containing related data records.
- Requires less space and has lower maintenance overhead.
- Slower than dense indexing for locating records.
- Example: A library catalog with sparse indexing for book titles.
-
Secondary Index:
- Generated by a field with unique values (usually a candidate key).
- Also known as a non-clustering index.
- Helps reduce the mapping size of the first-level index.
- Example: In a bank account database, a secondary index can be created for branch codes.
-
Clustered Index:
- Records themselves are stored in the index (not just pointers).
- Useful for non-unique columns.
- Helps identify records faster.
- Example: Grouping employee records by department in an HR database.
-
B-Tree Index:
- Balanced tree structure with nodes containing multiple keys and pointers.
- Efficient for range queries and equality searches.
- Commonly used in relational databases.
- Example: An online store’s product catalog indexed by product IDs.
Remember that each type of index has its advantages and drawbacks, and the choice depends on the specific requirements of the database system. Proper index maintenance is essential for optimal performance! 📊🔍